
Hateful Meme Detection
The first problem that I was introduced in my PhD was detecting hateful memes, proposed as an open challenge by Facebook in 2020. 2020 was the year of Covid, election, protests, and other turbulances in the society. That was probably the reason why hatred in memes became more prevalent, motivating computational researchers to develop automated systems to detect hateful memes.
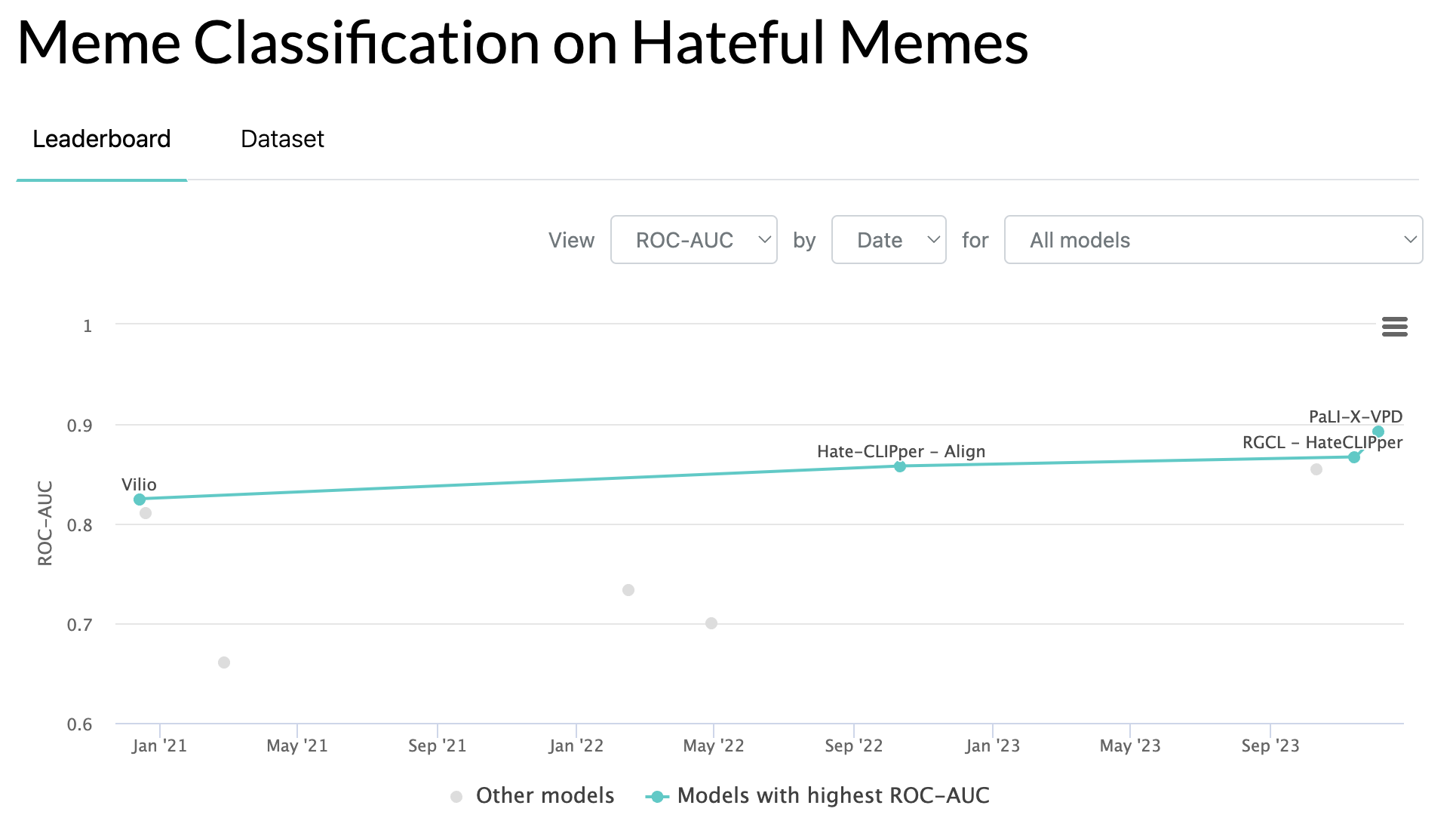
The leaderboard of Facebook Hateful Memes Challenge, via Papers With Code
The challenge was “solved” pretty well during the competition, where the winner, Ron Zhu, scored an AUROC of 0.84 (over 1.0). However, on Papers With Code (the crow-sourced leaderboard for ML tasks), only the runner up was recorded, which is Vilio with an AUROC of 0.825.
Notably, in 2023, Google introduced Flamingo, a vision-language model designed for few-shot prompting. While the 32-shot model got 0.7 AUROC, the fine-tuned model got 0.866. Unfortunately, none of the model checkpoints were released. I personally don’t know what the point of showing numbers without actually letting people try the model is. Given the move by Google, the community developed OpenFlamingo, which is, well, the open-source version of Flamingo. I am not sure if this open model is on par with the closed one, but this model is hugely popular with 3.5k stars on Github.
So, what is the current state of the art? It was achieved two months ago, in April 2024 by a Google-owned (again!) vision-language model called PaLI-X-VPD, where PaLI is a base model, X stands for the “large” size, and VPD means this model is the distillation result from a mechanism called Visual Program Distillation. This huge 55B model achieved 0.892 AUROC on the benchmark.
Now, people in the meme processing community is left with a big elephant in the room: should we still improve the performance on Hateful Meme Detection? The current performance is about 90%, which is pretty high. Note that human baseline was 85.7 in accuracy (Table 1 of this paper), which is not equivalent to AUROC, but should not be something higher than the current best AUROC. That said, improving this task means trying to improving super-human performance on a highly human-like task. I personanlly think this benchmark is saturated and the meme processing community needs more complex and interesting tasks to tackle.
Comments