
Another machine learning course
Last semester, I took a Machine Learning course at UTD. I like machine learning, so let’s review the course and see what it speaks about the epistemology of this field.

The course was taught by professor Vibhav Gogate. He’s an academic grandchild of Judeau Pearl, and advisee of the person who coined the term “deep learning”. The image suggests that he is a chill guy.
A taxonomy of ML methods
The prof gave us a framework to classify all machine learning methods, which is via three dimensions: representation (the parameters and how to do inference with them), objective function, and optimization algorithm. In other words, every ML method has all of those three, and a combination of those three uniquely determines an ML algorithm.
Given so, the course went through the following methods in Machine Learning. (This table is based on my understanding and may not correctly reflect the actual materials.)
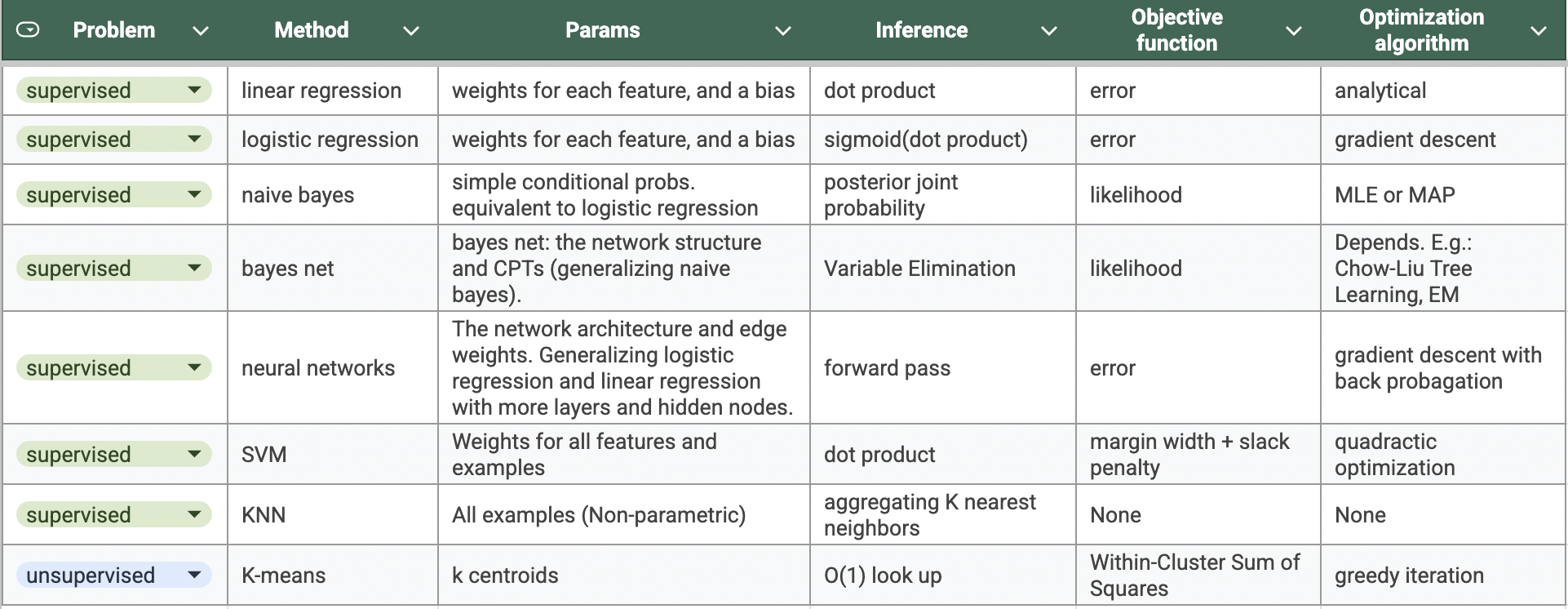
Classic machine learning methods
The course also cover some miscellaneous stuffs like ensemble methods, ways to evaluate ML hypotheses, etc. For more details, here are my cheatsheets for the midterm 1 and midterm 2.
The homework projects were formulated as research questions, which was kinda fruitful to do. But implementing code and running them for hours just so that the TA reads it for 15 minutes and gives me a grade is a bit pointless. Therefore, I published all my project code and report on my Github so that everyone can take a look. If you do take a look, look for report.pdf for a high-level overview first. Then look at the code starting from README.md. The projects are:
- NB and LR for spam detection
- Tree Classifiers for a synthetic CNF dataset and MNIST
- Collaborative Filtering for Netflix problem; SVM and KNN for MNIST
- K-means for image compression; EM with Bayes Net
Some reflections
Funnily, this is the fourth time I have taken “machine learning” in my academic journey:
- My first course was “Introductory Machine Learning with Python” at Fulright by Mr. Minh Hai Do (CoderSchool) in Spring 2020. It was the first Covid semester, in my first year of college. The course focused more on Python implementations of ML algorithms, mostly done via libraries. The maths behind were overlooked. There I learned that Kaggle competitions were the place to show off your ML skill and XGBoost is a popular algorithm to win those.
- My second course was “Machine Learning” by Andrew Ng on Coursera in Spring 2020 as well. I remembered that it had a good amount of math, but the covered topics were understandably outdated. The lessons I remember the mosts are the practical advices Andrew gave, such as where to improve in an ML pipeline. Projects were in Octave (an exotic flavor of Mathlab?) I took that course in parallel with a friend in STEM Club. (We liked learning together a lot at that time. That was partly motivated by the lack of technical CS courses at Fulbright back then.)
- The third course time was Vincent Ng’s visiting course at Fulbright, named “Introduction to Machine Learning”, offered in Fall 2022. This was when ChatGPT started to be popular and I was hoping that the professor would give us NLP assignments. He did not. Anyway, this course was more rigorous than the others, with more maths and more updated programming assignments. It broke down ML into supervised, unsupervised, and reinforcement learning, and tried to give enough attention to all of them. Fun fact: I was satisfied with the professor enough that I asked to become his PhD student.
If you allow me to go back even further, my first time interacting with “machine learning” was with my high school informatics teacher when he showed me “machinelearningcoban.com” (in Vietnamese) and “machinelearningmastery.com”. They were good reference sources but not the best for beginners. It was 2019, when the deep learning era was coming into its form. Even though I was really curious to learn, I did not know to access the good materials (like Andrew Ng’s course) to get started. But that’s okay, because I had learn it any way, one year later! And I took the course four times :)
Now in 2024, I am still learning new things that are actually very old, such as the Probably Approximately Correct model, Bayes net, and the cornerstone textbooks of the field. I got to know that Tom Mitchell’s ML textbook, despite being popular, is so old and outdated. Kevin Murphy’s books are more updated.
Given all of that time put into learning machine learning, I still have a feeling of not knowing enough in this field. There are things that I should know more, including:
- The satistical side of machine learning, such as Monte Carlo Methods for inference?, MCMC, Gibbs Sampling. Fun fact: Christian Robert, the leading expert in these things, is also the main inspiration for me to blog regularly!.
- The history of how people wen from traditional methods to transformers
- Generally, other methods in the machine learning toolkit, and their foundations.
- Is there always a unifying perspective to view everything?
- Is the current methods just prompt engineering, or there’s something deeper to it?
- Is Mixture Of Experts just a hyped name for ensemble? What has transformer fundamentally changed the problem of machine lnearing? (Or has it?)
- Why are people nowsadays tackle the classical problems (like regression, classification) with auto-regressive language-token-based LLMs only?
To conclude, I believe that learning about fundamental machine learning has a lot of benefits in this age. It helps put the GenAI hype into more informed perspective. It gives more rigor into this experimental field. It helps you stand a bit more still in the storm of LLM hype. So, keep learning!
Comments